
At GRIMM, we do a lot of vulnerability and binary analysis research. As such, we often seek to automate some of the analysis steps and ease the burden on the individual researcher. One task which can be very mundane and time consuming for certain types of programs (C++, firmware, etc), is identifying structures' fields and applying the structure types to the corresponding functions within the decompiler. Thus, this summer we gave one of our interns, Alex Lin, the task of developing a Ghidra plugin to automatically identify a binary's structs and mark up the decompilation accordingly. Alex's writeup below describes the results of the project, GEARSHIFT, which automates struct identification of function parameters by symbolically interpreting Ghidra's P-Code to determine how each parameter is accessed. The Ghidra plugin described in this blog can be found in our GEARSHIFT repository.
Background
Ghidra is a binary reverse engineering tool developed by the National Security Agency (NSA). To aid reverse engineers, Ghidra provides a disassembler and decompiler that is able to recover high level C-like pseudocode from assembly, allowing reverse engineers to understand the binary much more easily. Ghidra supports decompilation for over 16 architectures, which is one advantage of Ghidra compared to its main competitor, the Hex-Rays Decompiler.
One great feature about Ghidra is its API; almost everything Ghidra does in the backend is accessible through Ghidra's API. Additionally, the documentation is very well written, allowing the API functions to be easily understood.
Techniques
This section will describes the high-level techniques GEARSHIFT uses in order to identify structure fields. GEARSHIFT performs static symbolic analysis on the data dependency graph from Ghidra's Intermediate Language in order to infer the structure fields.
Intermediate Language
Often times, it's best to find the similarities in many different ideas, and abstract them into one, for ease of understanding. This is precisely the idea behind intermediate languages. Because there exist numerous architectures, e.g. x86, ARM, MIPS, etc., it isn't ideal to deal with each one individually. An intermediate language representation is created to be able to support and generalize many different architectures. Each architecture can then be transformed into this intermediate language so that they can all be treated as one. Each analysis will only need to be implemented on the intermediate language, rather than every architecture.
Ghidra's intermediate language is called P-Code. Every single instruction in P-Code is well documented. Ghidra's disassembly interface has the option to display the P-Code representation of instructions, which can be found here:
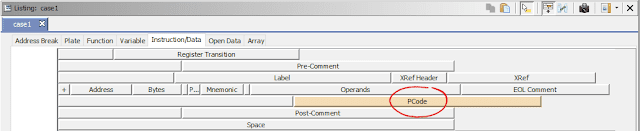
As an example of what P-Code looks like, a few examples of instructions from different architectures and their respective P-Code representation are shown below. With the basic set of instructions defined by P-Code specifications, all of the instructions from any architecture that Ghidra supports can be accurately modeled. Further, as GEARSHIFT operates on P-Code, it automatically supports all architectures supported by Ghidra, and new architectures can be supported by implementing a lifter to lift the desired architecture to P-Code.

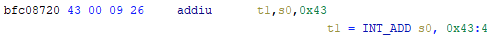
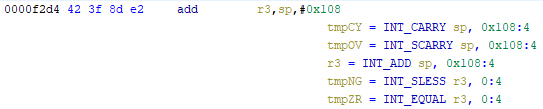
Symbolic Analysis
Symbolic analysis has recently become popular, and a few symbolic analysis engines exist, such as angr, Manticore, and Triton. The main idea behind symbolic analysis is to execute the program while treating each unknown, such as a program or function input, as a variable. Then, any values derived from that value will be represented as a symbolic expression, rather than a concrete value. Let's look at an example.
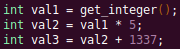
In the above pseudocode, the only unknown input is val1. This value is stored symbolically. Thus, when the second line is executed, the value stored in val2 will be val1 * 5. Similarly the symbolic expressions continue to propagate, and val3 will be val1 * 5 + 1337.
The main issue with symbolic execution is the path explosion problem, i.e. how to handle the analysis when a branch in the code is hit. Because symbolic execution seeks to explore the entire program, both paths from the branch will be taken, and the condition (and its inverse) for that branch will be imposed on both states after the branch. While sound in theory, many issues arise when analyzing larger programs. Each conditional that is introduced will exponentially increase the possible paths that can be taken in the code. Storing the symbolic state then presents a storage resource constraint, and analysis of the state presents a time resource constraint.
Data Dependency
Data dependency is a useful abstract idea for analyzing code. The idea is that each instruction changes some sort of state in the program, whether it is a register, some stack variable, or memory on the heap. This changed state may then be used elsewhere in the program, often in the next few instructions. We say that when the state affected by instruction A is used by another state B that is affected by some instruction, then B depends on A. Thus, if represented in a graph, there is a directed edge from A to B. The combination of all such dependencies in a program is the data dependency graph.
Ghidra's uses P-Code representation to provide the data dependency graph in an architecture independent manner. Ghidra represents each state (register, variable, or memory), as a Varnode in the graph. The children of a node can be fetched with the getDescendants function, and the parent of a node with the getDef function. As Ghidra uses Static Single Assignment (SSA) form, each Varnode will only have a single parent, and Varnodes are chained together through P-Code instructions.
Implementation
Using a combination of these techniques, we can identify the structs of function parameters. GEARSHIFT's method drew inspiration from Value Set Analysis, and is similar to penhoi's value-set-analysis implementation for analyzing x86-64 binaries. As a store or load will be performed at some offset on the struct pointer, the plugin can infer the members of a struct. To infer the size of the member, either the size of the load/store can be used (byte, word, dword, qword), or if two contiguous members are accessed, we know to draw a boundary between the two accessed members.
This plugin performs symbolic execution on the data dependency nodes. The P-Code instructions for a function parameter are traversed via a Depth-First Search (DFS) of the data dependency graph, recording all stores and loads performed.
P-Code Symbolic Execution
The plugin performs the actual symbolic execution by emulating the state in a P-Code interpreter for each P-Code instruction and storing the abstract symbolic expressions, with the function parameters as symbolic variables. Symbolic expressions are stored in a binary expression tree, which is defined by the Node class. Let's take an example of a symbolic expression and look at how the expression that would be stored.
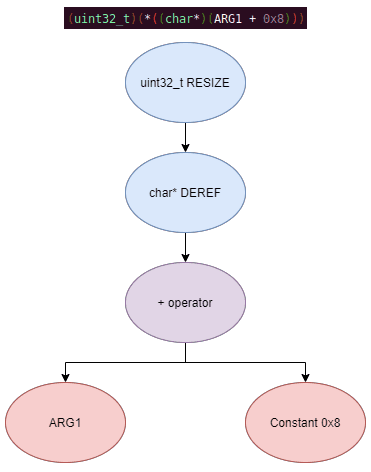
Now let's look at a P-Code interpreter, such as the INT_ADD opcode interpreter:
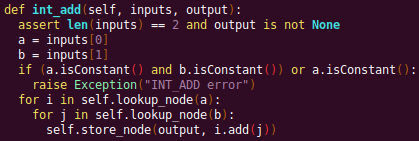
In the INT_ADD case, there are two parameters. The first parameter is usually a Varnode, and parameter two might be a constant or Varnode added to the first parameter. This function locates the symbolic expressions for the two parameters and outputs an add symbolic expression which combines the two. Most of the P-Code opcodes are implemented in a similar manner.
There are a few functions relevant to P-Code interpretation that require heavy consideration: lookup_node, store_node, and the CALL opcode. The first two functions handle the mapping between Ghidra's Varnodes and the symbolic expression tree representation, whereas the CALL opcode handles the interprocedural analysis (described in the next section).
One small problem occurs during the symbolic expression retrieval due to the nature of the DFS being performed. If an instruction uses a Varnode which has not had it's originating P-node traversed yet, the corresponding symbolic expression will not have be defined and be unavailable for use in the interpreter. To solve this issue, GEARSHIFT traverses backwards from the node whose definition is needed, until the node's full definition is obtained, with function arguments as the base case. This traversal is performed in plugin's get_node_definition function.
As an example of why this issue might occur, consider the below function and data dependency graph:
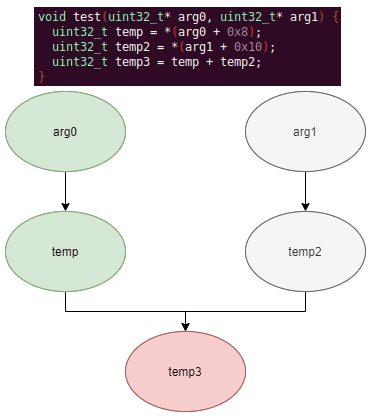
Because we are traversing in DFS manner from the function parameters, we may require nodes that have not yet been encountered. In this case, we are finding the definition of temp3 which depends on temp2, yet temp2 is not yet defined, since DFS has not reached that node. In this example, GEARSHIFT will traverse to temp2's and then arg1's Varnodes in order to define temp2 for use in temp3.
Interprocedural Analysis
As a function parameter's struct members may be passed into another function, it is extremely important to perform interprocedural analysis to ensure any information based on the called function's loads and stores will be captured. For example, consider the example programs shown below. In the first case, we have to analyze function2 to infer that input->a is of type char*. Additionally, a function can return a value that is then may later be used to perform stores and loads. In the second example, we need to know that the return value of function2 is input->a to be able to infer that the store, *(c) = 'C';, indicates that input->a is a char*.
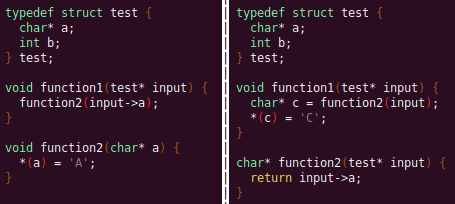
To support these ideas, two types of analysis are required. One is forward analysis, which is what we have been doing by performing a DFS on function parameters and recording stores and loads. The second is backwards analysis, i.e. at all the possible return value Varnodes from a function, and obtaining their symbolic definitions in relation to function parameters. This switching between forward and reverse analysis is where the project gets its name.
Struct Interpolation
The final step is to interpolate the structs based on the recorded loads and stores. In theory, it is simple to interpolate the struct with the gathered information. If a (struct, offset, size) is dereferenced or loaded, we know that value is a pointer to either a primitive, struct, or array. Now we just have to implement traversing this recursively and interpolating members recursively, so that we can support arbitrary structures. This is implemented through in GEARSHIFT's create_struct function.
However, one final issue remains: how do we know whether a struct dereference is a struct, array, or primitive? Differentiating between a primitive and a struct is easy, since a struct would contain dereferences, whereas a primitive would not. However, differentiating between a struct and an array is a more difficult problem. Both a struct and an array contain dereferences.
GEARSHIFT's solution, which may not be the best, is to use the idea of loop variants. Intuitively, we know that if we have an array, then we will be looping over the array at some point in the function. Thus, there must exist a loop and the array must be accessed via multiple indices. This method works well in the presence of loops which iterate through the array starting from index 0. However, we have to consider the case where iteration begins at an offset, and the case where only a single array index is accessed. In the first case, there is somewhat of a grey line between if this would be a struct or array. If no other members exist prior to the iteration offset, then it is likely an array. However, if there are unaligned or varying sized accesses, then it is likely a struct. In the second case, based on the information available (a single index access), it can be argued that this item is better represented by a struct, as the reverse engineer will only see it accessed as such.
Finally, once structs are interpolated, GEARSHIFT uses Ghidra's API to automatically define these inferred structs in Ghidra's DataTypeManager and retype function parameters. Additionally, it implements type propagation by logging the arguments to each interprocedural call, and if any of them correspond to a defined struct type, then that type is applied.
Results
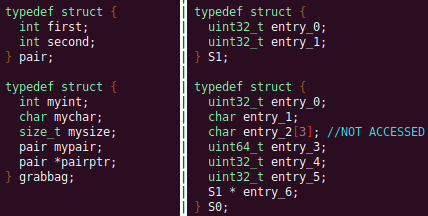

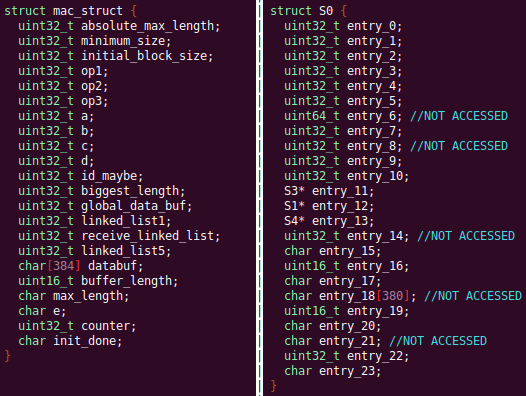
Future Work
- Multiple Accesses to the Same Structure Offset. If a structure has a union that accesses the data in multiple ways, GEARSHIFT will not be able to handle this case.
- Duplicate Structures. Currently, two different structs will be defined even if the same struct is used in multiple places. One simple solution may be to merge structures with similar signatures. However, this approach will likely result in false positives.
- Function and Global Variables. At the moment, GEARSHIFT only operates on function parameters and will not recover structures that are used as function/global variables.